
决策树的尝试
House Prices - Advanced Regression Techniques 给定 79 个房屋的特征,基于 1460 个房屋特例的训练集预测其他的房屋价格,最终评判均方误差 (Mean Squared Error, MSE)
执行
决策树
对于已有的多个特征,很容易想到使用特征去衡量房屋的价格,例如车库面积越大的房屋往往价格更高,而我们正是需要这种「趋势」去对房屋进行量化
数据处理
无论是用于训练的训练集还是用于评估的测试集,都需要对文件读取并将数据清洗才能用于处理
# 数据类型
list(set(row_train_dataset.dtypes.tolist()))
-- output --
[dtype('O'), dtype('int64'), dtype('float64')]检查数据的类型,除去整形与浮点的数值型数据,还有 ‘O’ 型,也就是实际上对应的字符型,部分特征并不是数字,而是自然语言的描述,如:
GarageQual: Garage quality
Ex Excellent
Gd Good
TA Typical/Average
Fa Fair
Po Poor
NA No Garage很显然对于这类数据没法直接进行处理,通过字符串没有办法判断出谁大过谁 因此需要对这类数据进行独热编码(One-Hot Encoding),即将每一个具体的可选值上升为一个字段,即每一个房屋都增加几个维度:Garage quality E、Garage quality G、Garage quality T.... 这样就能够正确评估这些字段对于房屋售价的影响,但这一做法同样存在缺点
- 维度爆炸:将可选项上升为一个新的维度,高维将会带来巨大的计算量
- 深度浪费:对于车库质量这一原属性,实际上每个选项间是有「大小」之分的,也就是可以映射为数值的大小。独热编码下的维度只有01两个值,却会占用多个节点
# 删除 id
row_train_dataset = row_train_dataset.drop('Id', axis=1)
# 备份id
test_ids = row_test_dataset['Id']
row_test_dataset = row_test_dataset.drop('Id', axis=1)
# 数值数据
dataset_train_num = row_train_dataset.select_dtypes(include = ['float64', 'int64'])
dataset_test_num = row_test_dataset.select_dtypes(include=['float64', 'int64'])
# 字符数据
dataset_train_str = row_train_dataset.select_dtypes(include=['O'])
dataset_train_str_encoded = pd.get_dummies(dataset_train_str) # 独热编码
dataset_test_str = row_test_dataset.select_dtypes(include=['O'])
dataset_test_str_encoded = pd.get_dummies(dataset_test_str) # 独热编码
X = dataset_train.drop('SalePrice', axis=1) # 第一列 key
y = dataset_train['SalePrice'] # 对应售价
# 测试集对齐训练集维度
dataset_test = dataset_test_init.reindex(columns=X.columns, fill_value=0)
# 训练
# 使用随机森林
tree_model = DecisionTreeRegressor(random_state=1)
tree_model.fit(X, y) # 这一步就是机器在穷举问题、寻找最佳切分点的过程
# 预测
predictions = tree_model.predict(dataset_test)
# 输出
output = pd.DataFrame({
'Id': test_ids, # 把第一步备份的单列拿回来用
'SalePrice': predictions # 填入模型刚刚算出的结果
})
output.to_csv('submission.csv', index=False)
print("预测结果生成完成")随机森林
单一的决策树有可能会被某些训练集中过于特殊的特征所误导,从而忽略了某些特征的作用,因此可以引入森林 通过创建多颗树,每一棵树通过数据抽样(每次训练取到的样本数据都是随机的)和特征抽样(每一个节点分支只能看到部分的特征),这样便能得到多颗不相同的树,对于一个测试样例取多棵树的平均值,避免某种树状下受到某一极端数据的影响
# 训练
# 使用随机森林
tree_model = RandomForestRegressor(n_estimators=150, random_state=1)
tree_model.fit(X, y) # 这一步就是机器在穷举问题、寻找最佳切分点的过程可行的优化
观察多个特征下的房屋频率 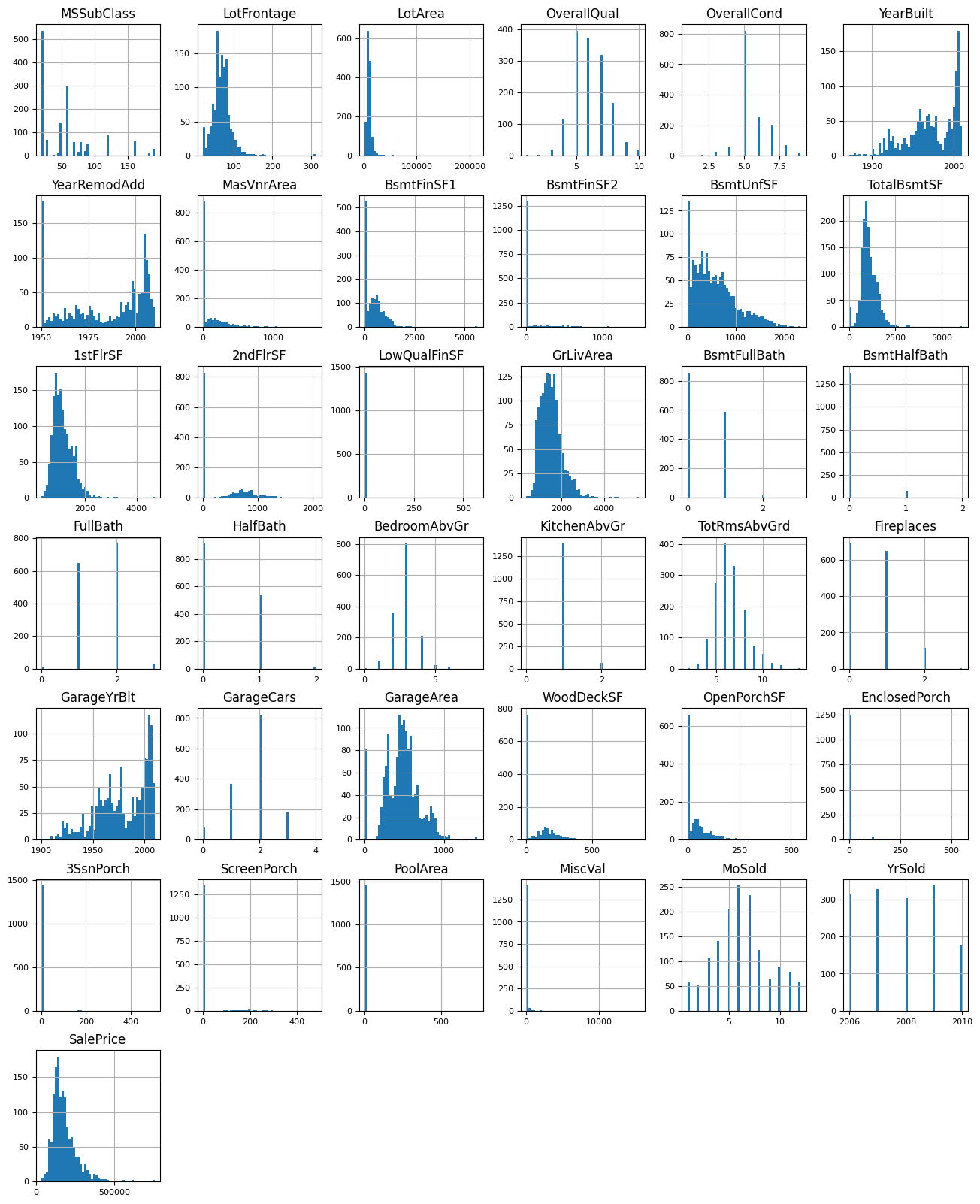 存在部分特征下,频率分布差异过于明显,例如 PoolArea 中的绝大多数数据都是 0,但假设有一个高级房屋用于 512 的面积,还有一些房屋仅有几十的面积,但因为 0 的面积更多,节点划分时会以几百为分界线,将那几个有游泳池但面积小的房屋与没有游泳池的房屋归为了一类。但实际上,只有有游泳池其价格都不会低廉,所以说这一分支是几乎无效的
存在部分特征下,频率分布差异过于明显,例如 PoolArea 中的绝大多数数据都是 0,但假设有一个高级房屋用于 512 的面积,还有一些房屋仅有几十的面积,但因为 0 的面积更多,节点划分时会以几百为分界线,将那几个有游泳池但面积小的房屋与没有游泳池的房屋归为了一类。但实际上,只有有游泳池其价格都不会低廉,所以说这一分支是几乎无效的
优化
讲这类数据进行二元化并独热编码处理,这样简单的划分为有游泳池与无游泳池之分,能够进行有效划分